Scalability issues
Wiredflow is a lightweight tool for fast development and services launching. However, a developed prototype may become a full-fledged production solution. In this case it may be necessary to scale the service. This document comes with instructions and guidelines to solve such an issues. Wiredflow may well be massively scalable!
Common issue description
Let's start with a description of the task. Scalability refers to the ability to increase the computational resources of the service when the load increases. Let's consider an example. Suppose that the service was using a server A with 4GB of RAM and 4 core processor. It was pretty good for 1000 data items processing per day. However, the service became popular and now it is process not 1000 data items per day, but 10000. The first solution is we can rent a more powerful server B, but that is expensive. It would be much more efficient to use 10 servers like the original one. But how do we configure Wiredflow to make it work properly with the new setup?
The initial configuration of the service will approximately be as follows:
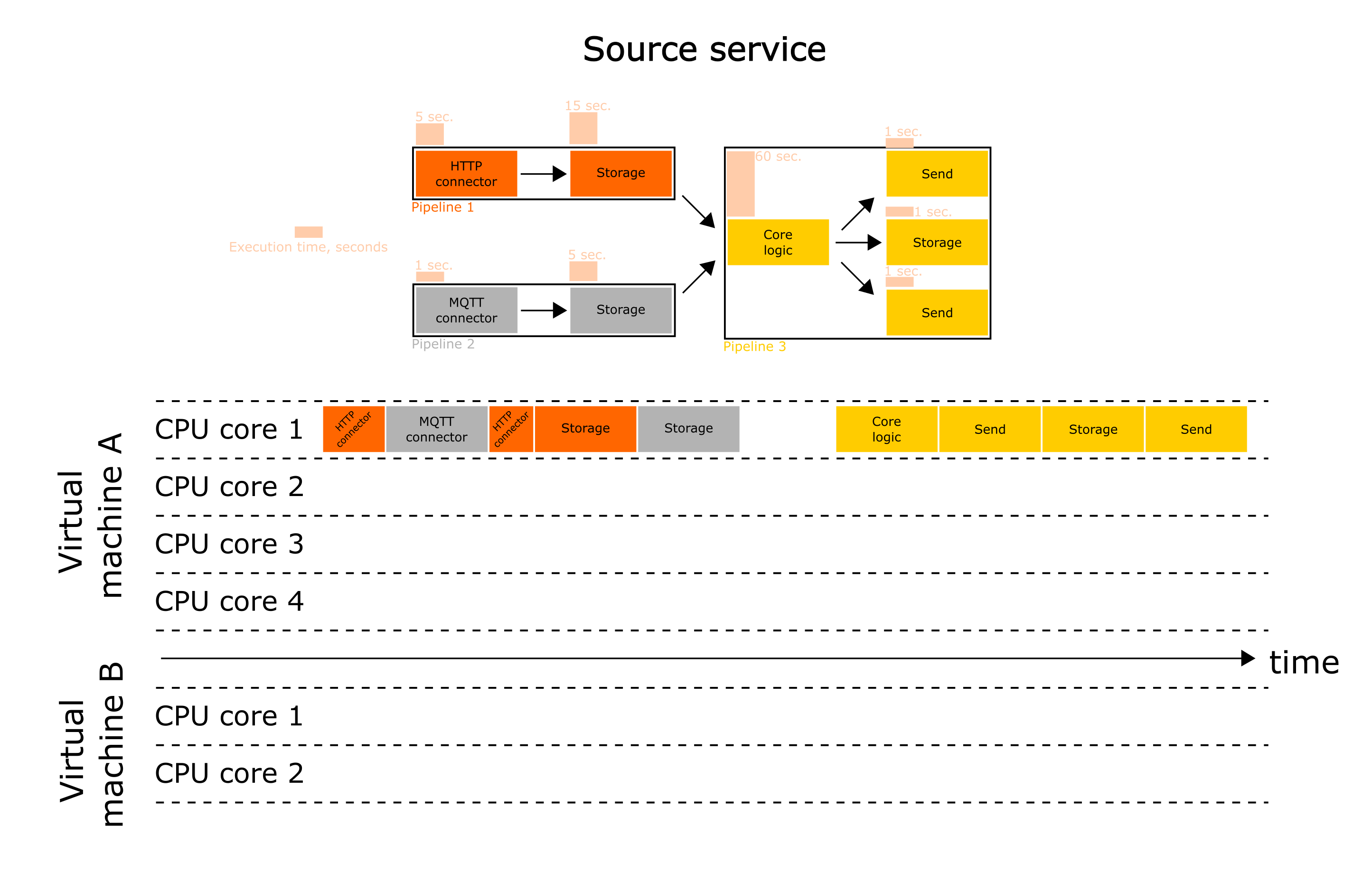
If we use the default wiredflow configuration, all our pipelines (there are 3 of them) run in threads. This allows the interpreter to switch the context when a particular stage is pending (e.g. a response from an external service). This allows the interpreter not to idle when several pipelines have to be computed simultaneously.
Suppose that we want to speed up each pipeline. Let's try!
Simple tips (thread into process)
If the service is not running fast enough and:
- your server resources are not being fully utilized
- number of pipelines in the service more than 2 and less than CPU cores on your machine
- some pipelines are occupied by computationally expensive tasks
Then you should try to run the service in parallel mode.
Using the parameter use_threads=False wiredflow will start the pipelines not in threads (as is done by default), but in processes.
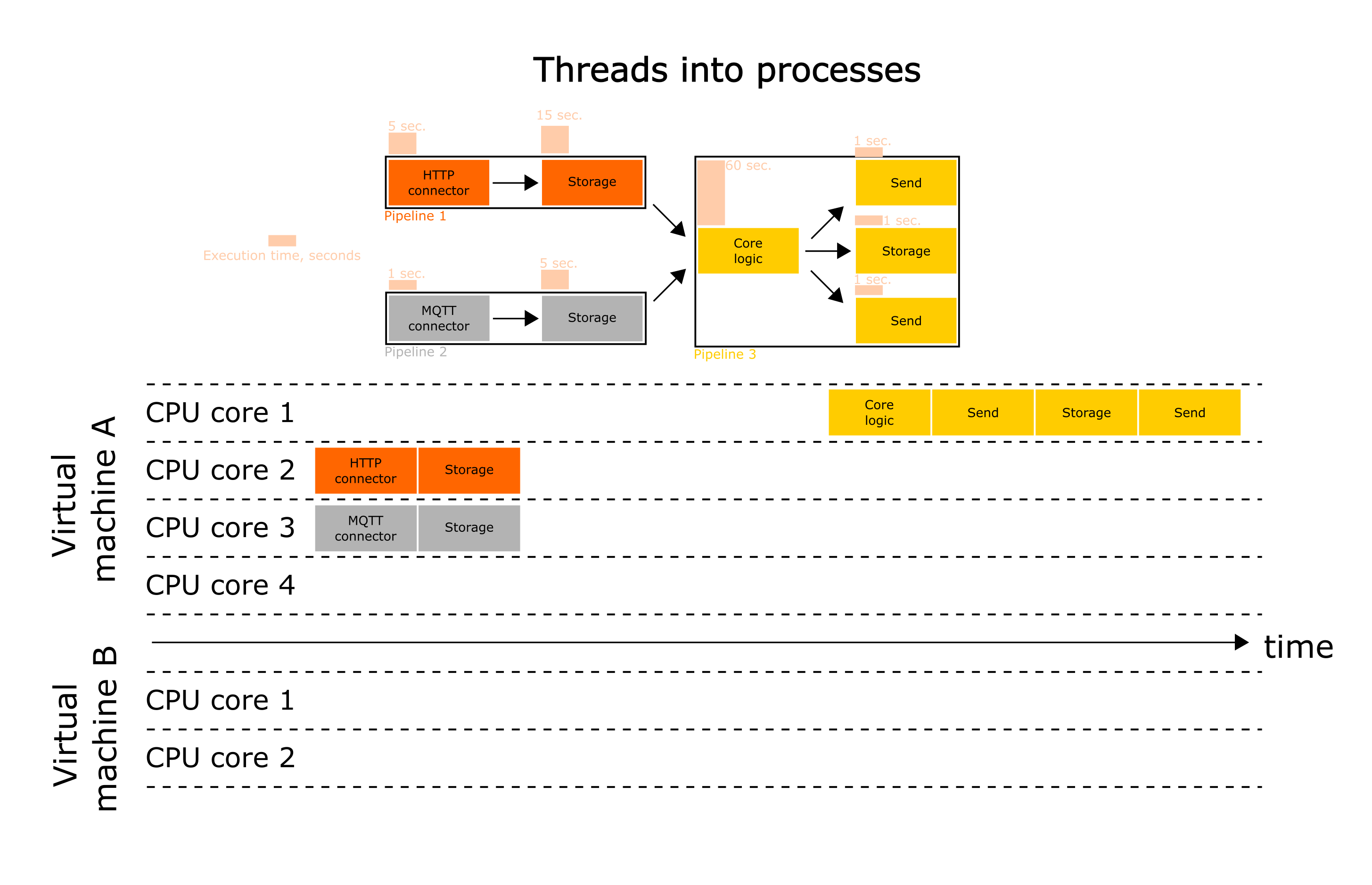
This trick does not speed up service at the stages level. It allows more efficient use of the multicore processor architecture on the pipelines level. However, this approach does not always help to speed up your service. If that doesn't help, then see the tips below.
Tokenization
The first "real" approach for scaling the service is tokenization. It consists in dividing the original service into individual blocks. This is another interpretation of the classical approach to decomposition of tasks in programming.
Tokenization is a rather general term and can be interpreted in three ways in this documentation according to wiredflow specifics (per levels):
- Stage into stages - Dividing an operation into several sequential ones. It is also possible that some parts can be performed simultaneously (good reason to pack them into different stages). This procedure is preliminary - there are rare cases when it is possible to allocate separate pipelines in a service. As a rule, first it is necessary to isolate tasks within the stages;
- Pipeline into pipelines - Splitting one pipeline into several new ones. This will allow the service to "switch" between tasks more efficiently;
- Flow into flows - Splitting one flow (service) (e.g. one
.pyfile) into several new ones (2, 3, 5 new.pyfiles). Separate.pyfiles in this case mean that separate services can be run on different servers.
Tokenization is not the straightforward process. It requires a deep understanding of the business logic of the implemented service. At the same time, such optimization process is poorly automated. Nevertheless, it will allow to critically evaluate the implementation of business logic and increase the efficiency of the service not at the expense of "hardware", but due to a more intelligently designed architecture of the solution. This also means that this improvement can be "free" - you may not have to take out a new server lease (relevant for the first two levels of tokenization)
Check page with more detailed recommendations.
In the current example we did the following:
- Split the core logic into two parts, which can be executed simultaneously (Stage into stages);
- Compiled two pipelines from one with core logic (Pipeline into pipelines);
- Pipeline 4 runs on a separate, more powerful virtual machine (Flow into flows).
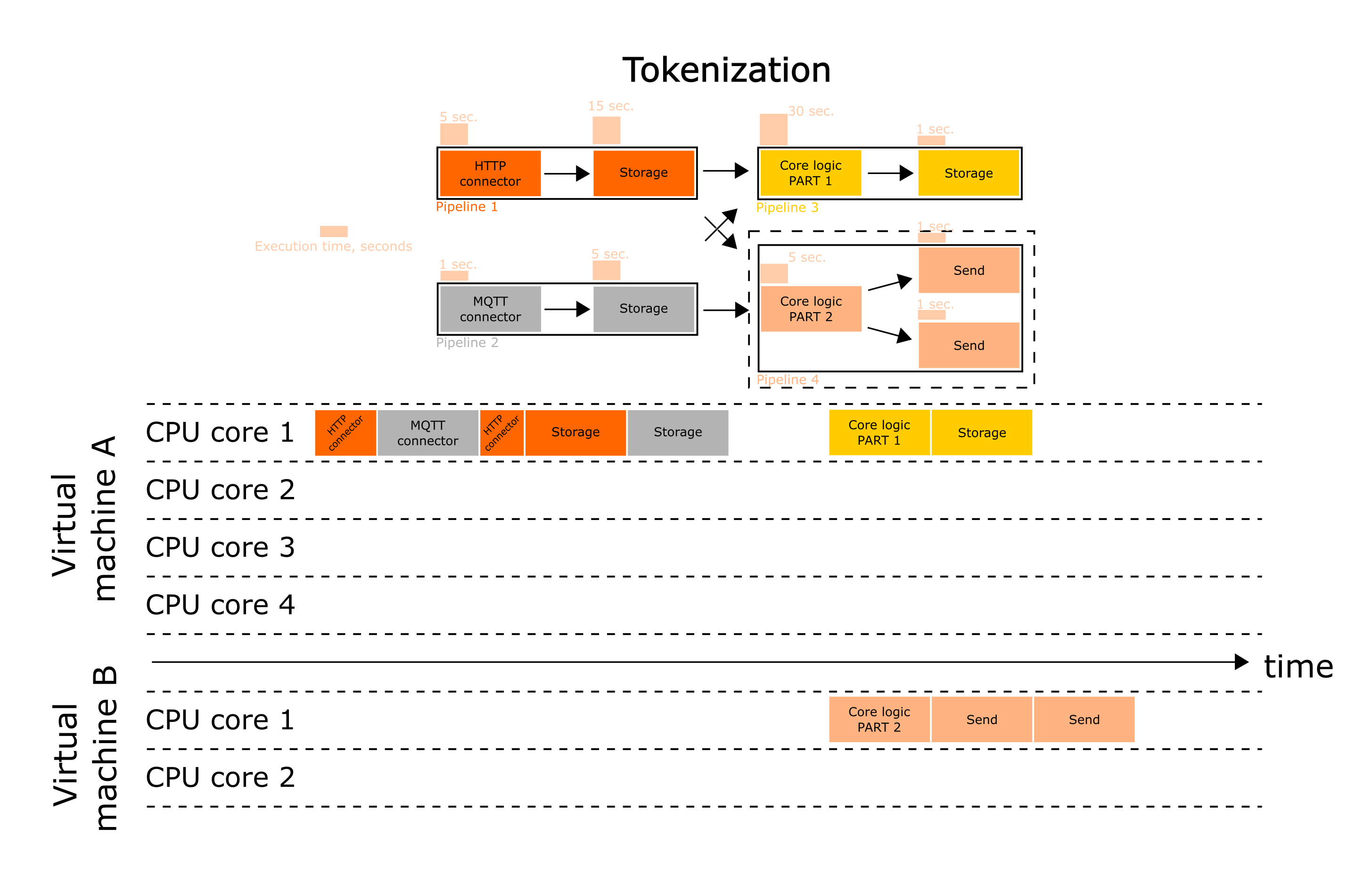
Thus, we have simultaneously reduced the execution time of individual stages as well as of entire pipelines and the service.
Remote launch
Another approach is to remotely run the most computationally expensive operations on remote (surprisingly) servers. In this case, Wiredflow will become a tool for orchestrating the system and will provide consistency.
It is worth noting that the frameworks are not in competence with each other. On the contrary, Wiredflow and Apache Airflow, for example, can work together. There are no conceptual restrictions to configuring lightweight Wiredflow pipelines and complex scalable Apache Airflow-based pipelines in the same service. Therefore, you can always use the tools used in your team to remotely run high-load parts of the applications.
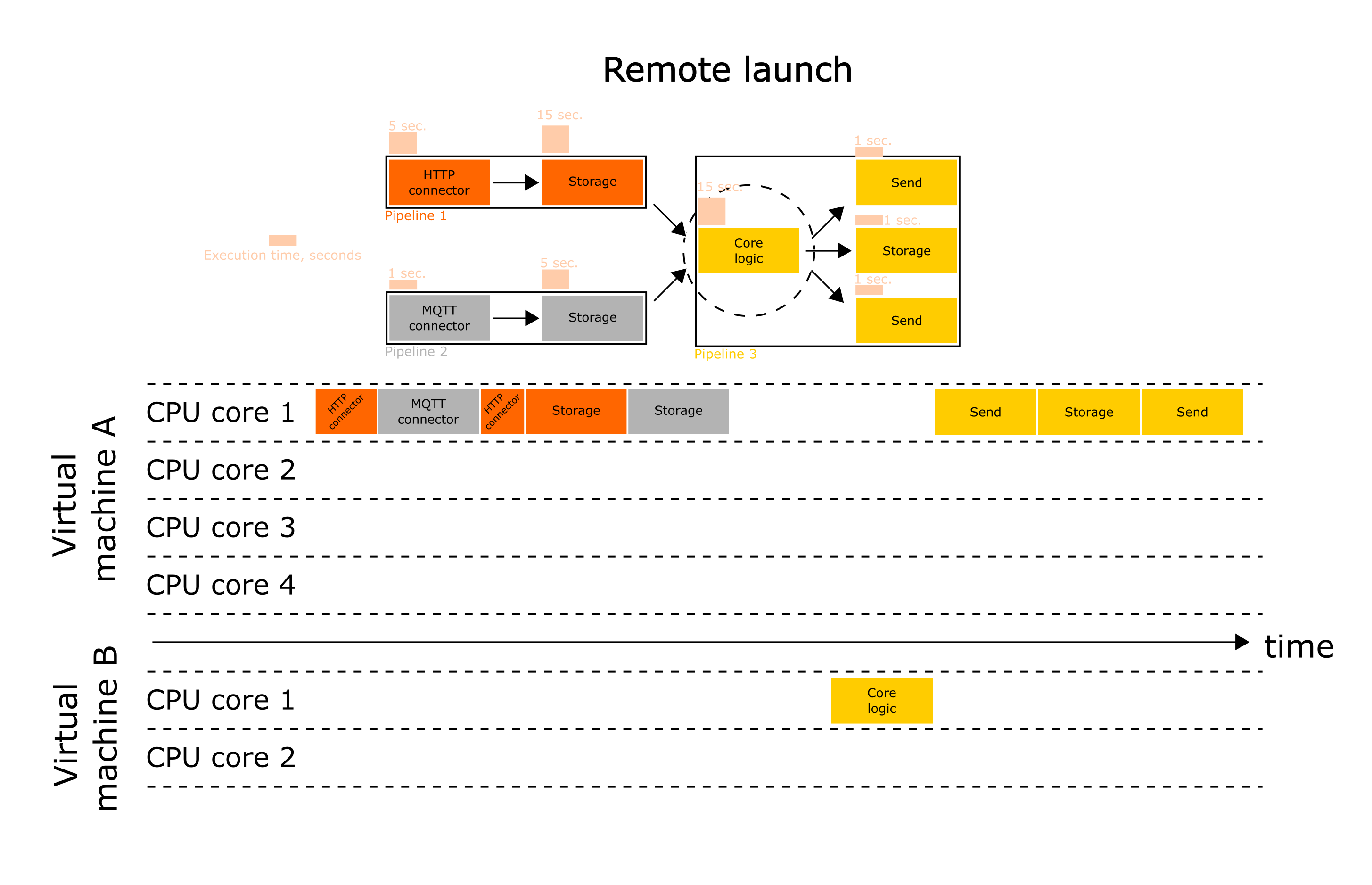
As can be seen from the scheme, we simply use a more powerful server to execute the most computationally intensive stages.
For more information on remote start and its capabilities, see this more detailed guide.
Combination
Scaling can and should be done until you are satisfied with the throughput of the service or other characteristics. To achieve this goal, we insist strongly encouraging tokenization and remote launch. This can significantly optimize the service