Storages description
This section discusses the crucial topic about data storage. If choose the wrong way to store data, it can become a critical bottleneck for the entire service. Therefore, on this page we suggest to explore in detail what kind of storage is worth using in different cases.
Files as local storages
Let's start with a very simple example. You can use regular files! Because sometimes you don't need to complicate things. Especially during the first stages of development, when it is carried out locally on the developers' laptops.
The following options can be used to access storage files in wiredflow:
json- save data into JSON file (good for variable structure data)csv- save data into CSV file (good for data with fixed structure)
JSON in this case can be considered as a very simplified analogue of MongoDB. And csv is an example of a relational database, such as PostgreSQL.
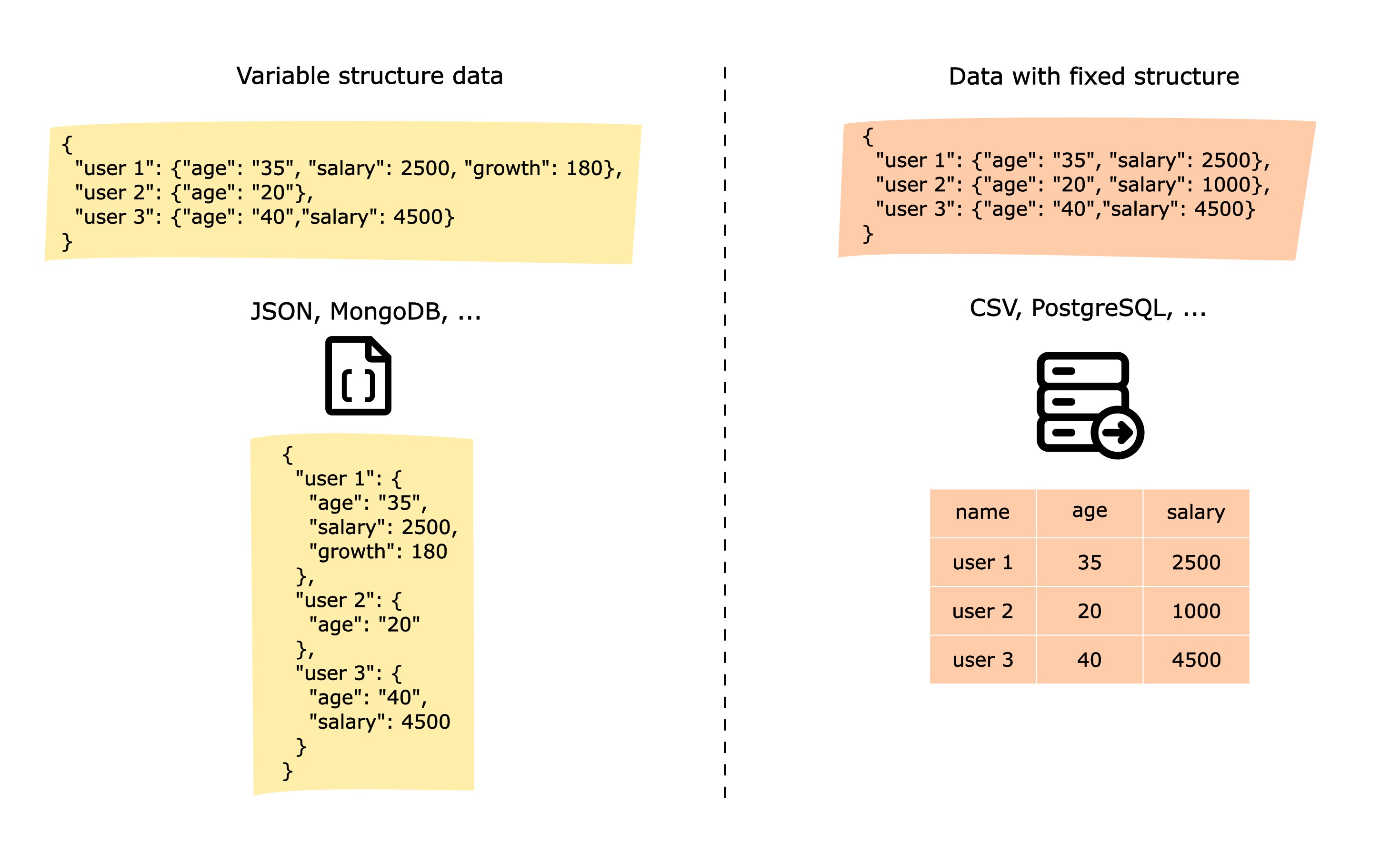
Warning! Please do not use the files as data storage in "production" solutions! Storing data in files is convenient only in the first stages of service development. Then switch to using a suitable database.
Usage examples
As discussed in the previous examples, adding a storage to the pipeline structure can be performed with the
method with_storage(). The most important argument in this method is configuration with two options for
files storages: json and csv. Additional parameters for files storages are:
-
folder_to_save- path to the folder where to save json or csv files. A file with the following name will be created in the specified folder:<configuration>_in_<pipeline_name>.jsonfor JSON file and<configuration>_in_<pipeline_name>.csvfor csv file where<configuration>is the name of applied configuration and<pipeline_name>is pipeline name -
preprocessing- name of preprocessing to apply or list of preprocessors Possible options:add_datetime- add datetime label to obtained dictionary
-
mapping- name of mapping procedure to apply during save stage Possible variants:update- update dictionary with new kye-values pairsoverwrite- create file from scratchextend- if the structure list-related - then just add new dictionaries to existing ones
Let's look at examples of work on a service we are already familiar with from the "Single thread service with HTTP connector" section. The source function was modified a little bit to make it convenient to transfer the parameters into the storage stage:
from pathlib import Path
from wiredflow.main.build import FlowBuilder
from wiredflow.mocks.demo_bindings_threads import launch_demo_with_int_http_connector
def launch_flow_with_local_storage_config(storage_configuration: str, **params):
"""
Example of usage local files as storages
:param storage_configuration: name of configuration to be applied
"""
flow_builder = FlowBuilder()
flow_builder.add_pipeline('http_integers', timedelta_seconds=2)\
.with_http_connector(source='http://localhost:8027',
headers={'accept': 'application/json',
'apikey': 'custom_key_1234'})\
.with_storage(storage_configuration, **params)
flow = flow_builder.build()
launch_demo_with_int_http_connector(flow, execution_seconds=10)
Let's start with the typical example of running a service to save results to a json file:
if __name__ == '__main__':
# Save data into json file into new folder
launch_flow_with_local_storage_config('json', folder_to_save=Path('./json_storage'))
Saved messaged obtained from HTTP endpoint:
[
{
"Generated random number": 66
},
{
"Generated random number": 25
},
{
"Generated random number": 39
},
{
"Generated random number": 68
},
{
"Generated random number": 27
}
]
If there is a need to save data into csv file - just change the configuration name:
if __name__ == '__main__':
launch_flow_with_local_storage_config('csv', folder_to_save=Path('./csv_storage'))
Customization
In the example of saving to a JSON file, let's use some built-in capabilities to modify data, which will be loaded.
Start with preprocessing - add label datetime_label into each item during saving procedure:
if __name__ == '__main__':
launch_flow_with_local_storage_config('json', preprocessing='add_datetime', folder_to_save=Path('./preprocessing'))
Service output into the JSON file will be the following:
[
{
"Generated random number": 89,
"datetime_label": "2023-04-17 15:20:54.594447+03:00"
},
{
"Generated random number": 54,
"datetime_label": "2023-04-17 15:20:56.598781+03:00"
},
{
"Generated random number": 85,
"datetime_label": "2023-04-17 15:20:58.603439+03:00"
},
{
"Generated random number": 59,
"datetime_label": "2023-04-17 15:21:00.609836+03:00"
},
{
"Generated random number": 90,
"datetime_label": "2023-04-17 15:21:02.615213+03:00"
}
]
Different mapping strategies can also be applied.
Mapping in this case refers to the process of comparing values that are currently being saved to the file with
those already written to the storage.
For example, you can notice that the values received via HTTP are dictionaries, in which the key is always
the same - "Generated random number".
If we want to save a new values, ignoring the old ones, we can use the parameter mapping and set overwrite:
if __name__ == '__main__':
launch_flow_with_local_storage_config('json', mapping='overwrite', folder_to_save=Path('./overwrite'))
Thus, the file will always contain only the latest actual data sample:
[
{
"Generated random number": 33
}
]
Thus wiredflow has several built-in functions that enable pre-processing and saving values to files. Don't worry if your service has multiple pipelines using the same json or csv file - wiredflow has internal mechanisms to synchronize threads and processes. It ensures that pipelines will not get into a race condition or unexpectedly corrupt the file while reading or saving operations.
However, sometimes it is necessary to use more reliable storage than files.
Databases
This section discusses general information about using databases in Wiredflow pipelines. The use (with code examples and so on) of specific databases is discussed in more detail in the following sections.
In this section we will give some arguments in which cases what database should be used. Databases with which there is native integration will be considered here. However, feel free to use any database that suits your needs and integrate it through the customization mechanisms.
The wiredflow library is currently under active development, so for now there is only integration with the MongoDB database. Integration with SQLite and other databases is planned.