Tokenization
This document details the features of tokenization of wiredflow services. The goal of tokenization is to improve service performance. This can be achieved by decomposing tasks on three levels:
- Stage into stages (preparation);
- Pipeline into pipelines;
- Flow into flows.
The tokenization process will be discussed using the example of a service, which was shown on the previous page - Scalability issues:
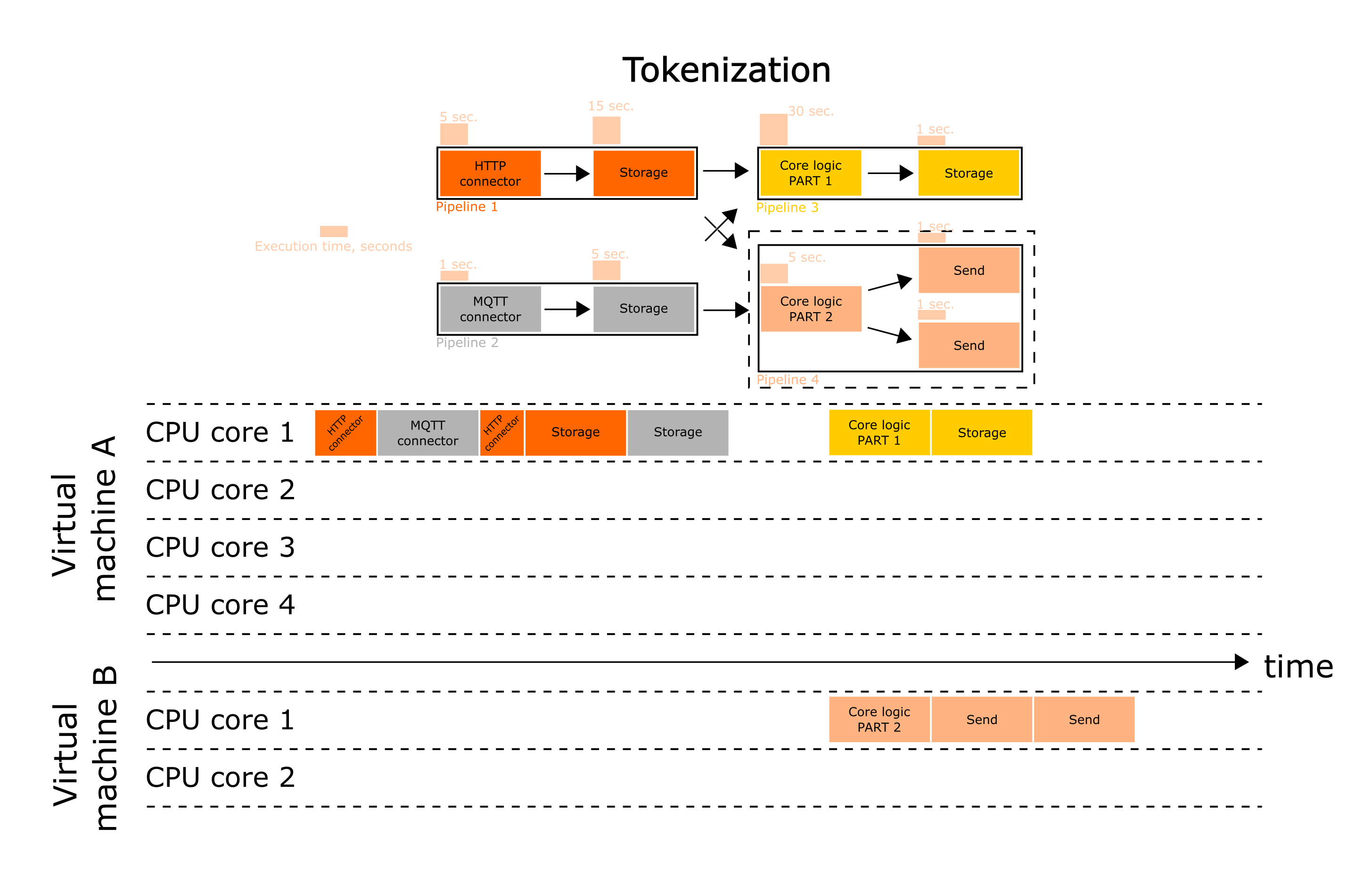
As it was mentioned, here we did the following:
- Split the core logic into two parts, which can be executed simultaneously (Stage into stages);
- Compiled two pipelines from one with core logic (Pipeline into pipelines);
- Pipeline 4 runs on a separate, more powerful virtual machine (Flow into flows).
Below there is a more detailed investigation of how the tokenization per levels was performed.
Warning! All the examples in the common description section are toy-like and formulated in a way that makes it easier to understand the main ideas. If you need more real-world examples with code snippets, explore the Tutorials section.
Stage into stages (Preparation step)
The first thing worth paying attention to is how the code is organized. Tasks should be decomposed into the simplest actions, which are placed in wiredflow stages.
If any tasks (stages) run very slowly, consist of a lot of code and use complex multi-step logic, it may be worth to divide these tasks into smaller ones.
For instance, let's imagine that core logic is still monolith and performs the two operations sequentially:
- Load data from database 1 and 2 - map it and save aggregation into database 3;
- Load other data from database 1 and 2 - use another logic for aggregation, perform some calculation and send reports to 2 endpoints via HTTP POST method.
Then this logic can be decomposed into 2 functions, which can be executed isolated from each other.
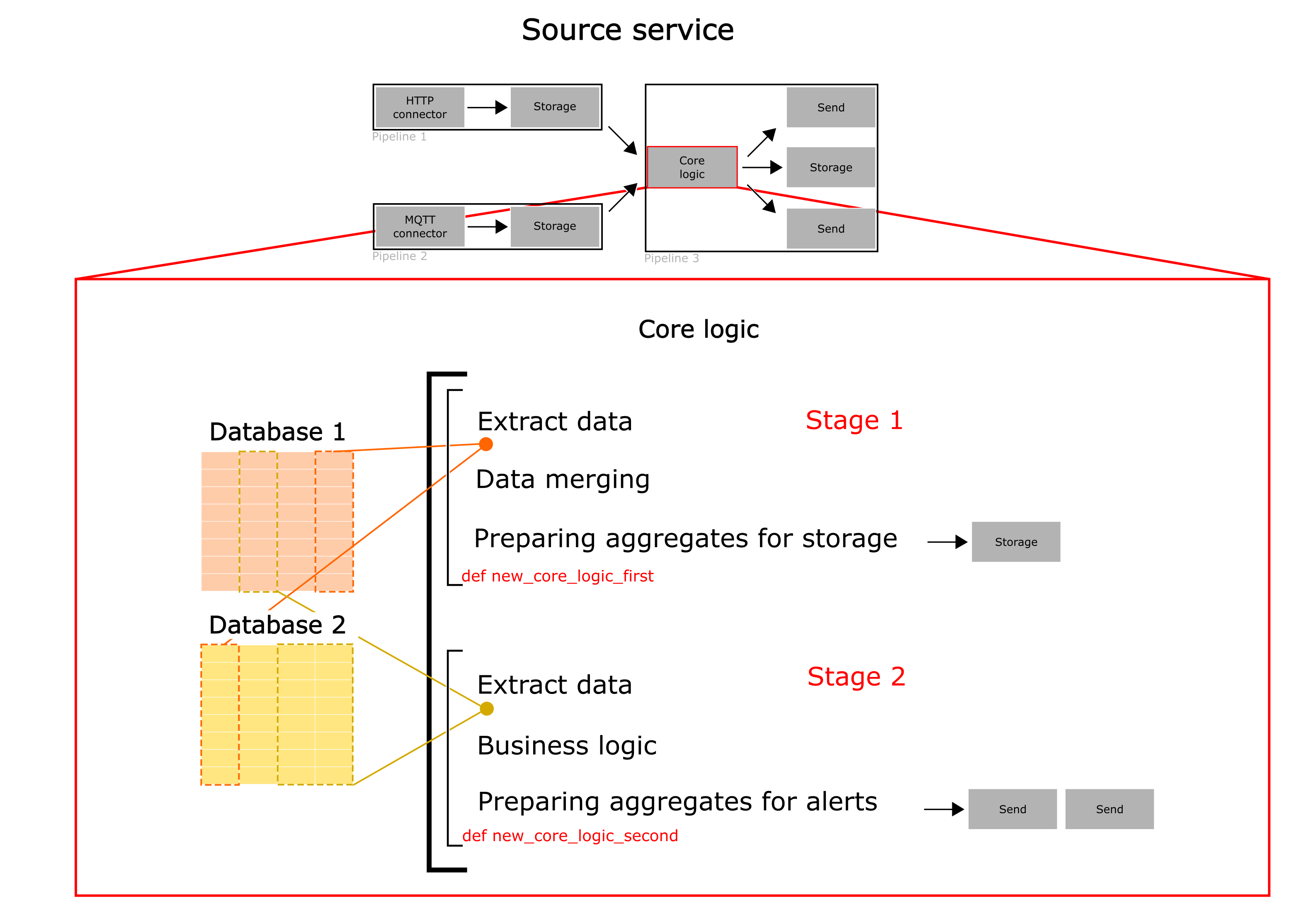
Thus, the original structure of the service was not changed for now - we just find the place in the service and split stage into two functions for further modifications.
Pipeline into pipelines
Thus, core logic can be divided into two parts which may be packaged into pipelines:
- Storage logic - part of core logic, which include extracting data from databases, perform transformation A and saving into another database
- Send logic - part of core logic, which include extracting data from databases, perform transformation B and send
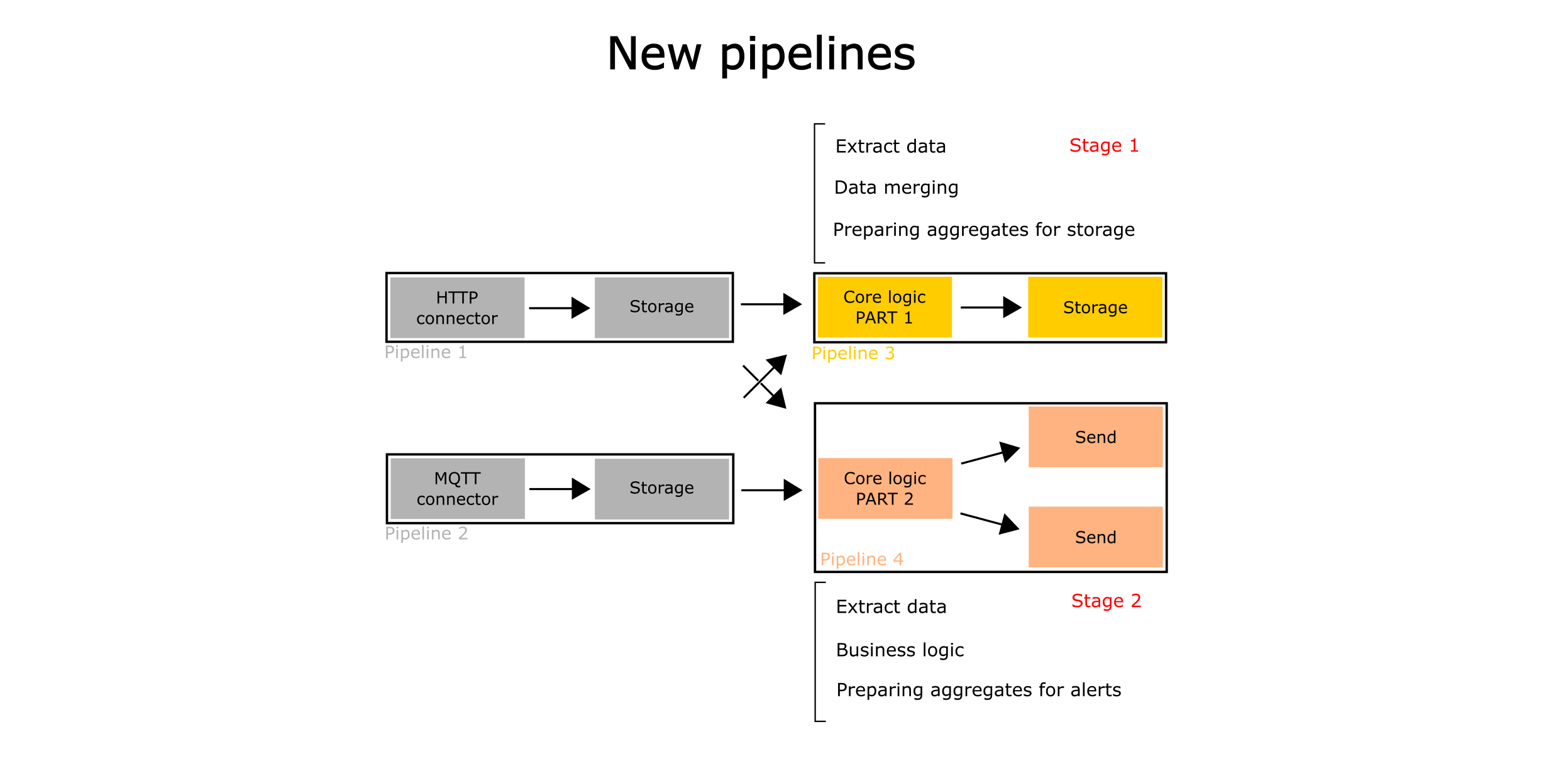
Flow into flows
Finally, if the resources of one virtual machine are not sufficient to calculate the pipelines fast enough, it is possible to separate some pipelines into individual services (flows) and run them independently. Thus, instead of one service (flow), several services (flows) are started.
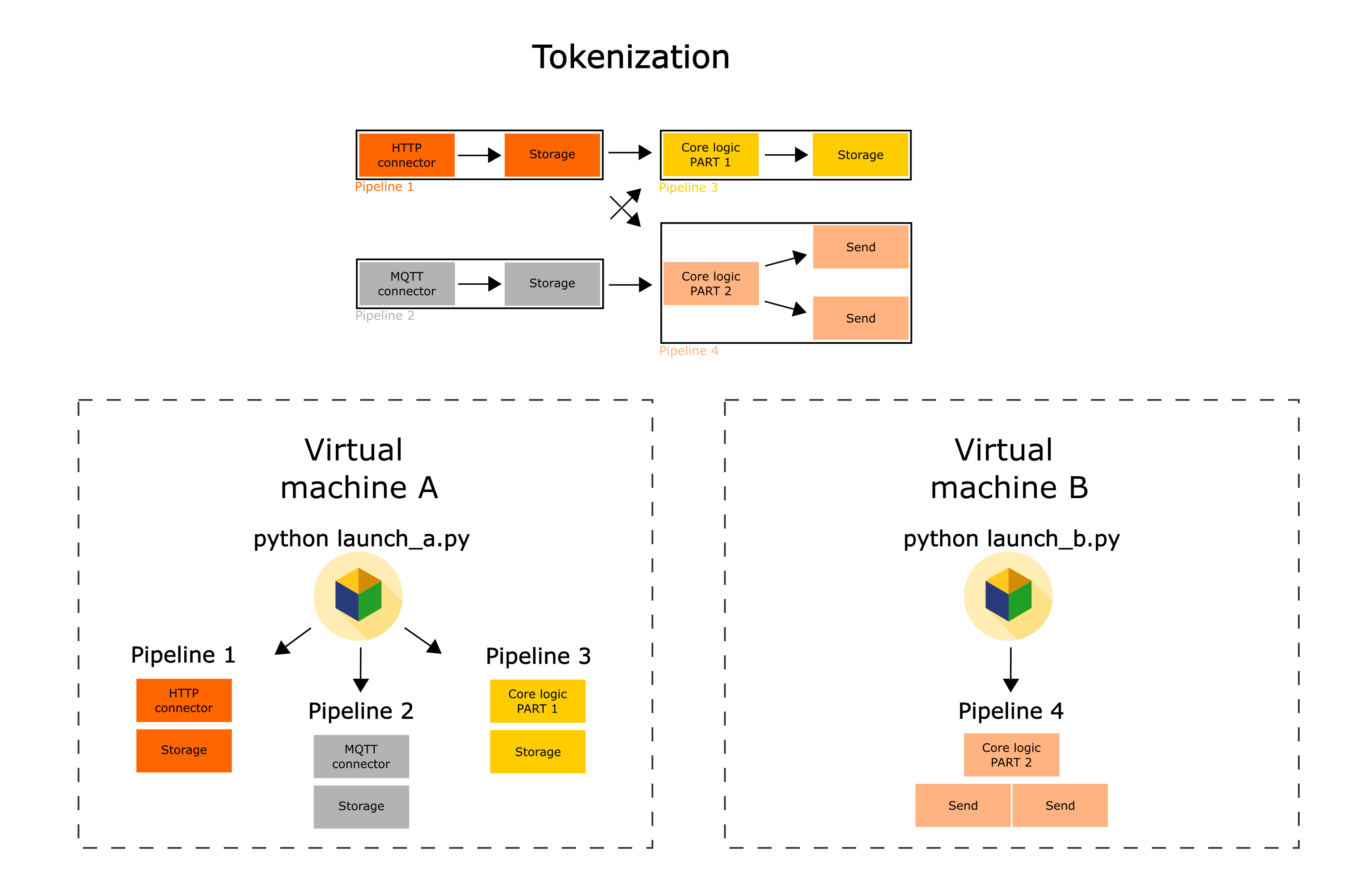
Important notes
It is usually better to run wiredflow services through one entry point (one .py file).
This will make it easier for you to manage the entire branched service.
Wiredflow keeps track of all its pipelines configured through one service.
This means that if the service is computed, then every pipeline in its structure works correctly.