Wiredflow-based service with several pipelines
This document discusses the most interesting part of wiredflow functionality. The library allows launching several pipelines in one service (flow). Such flows are called hereinafter "multi-pipelines" or "complex" services.
When might it be necessary to run multiple pipelines?
Suppose there is a need to collect data from various sources, aggregate it in a custom way, and then save it to a new database. If there is a need to implement such a complex service through a single entry point using relatively few computing resources (e.g. to run all ETL processes in one virtual machine), then wiredflow is a good choice.
Using the functionality of pipelines becomes possible:
- Ensuring ETL service consistency without overhead. Pipelines notify each other if something goes wrong during execution. This means that if one pipeline fails, the others stop, too. All pipelines run on the same virtual machine (if tokenization is not used), so they are orchestrated by Python without additional abstractions
- Run each ETL process in a separate Python thread (or process, for more information; check "Launch multi-pipelines service through processes" section). This will ensure efficient use of computational resources, especially when there are many I/O operations in the pipelines.
So if your ETL process includes multiple data sources, custom processing logic, and requires synchronization (consistency), then complex services based on wiredflow is a good tool to use.
In the picture below you will find some examples of complex services that can be created with wiredflow (pipelines in their structure are highlighted in red):
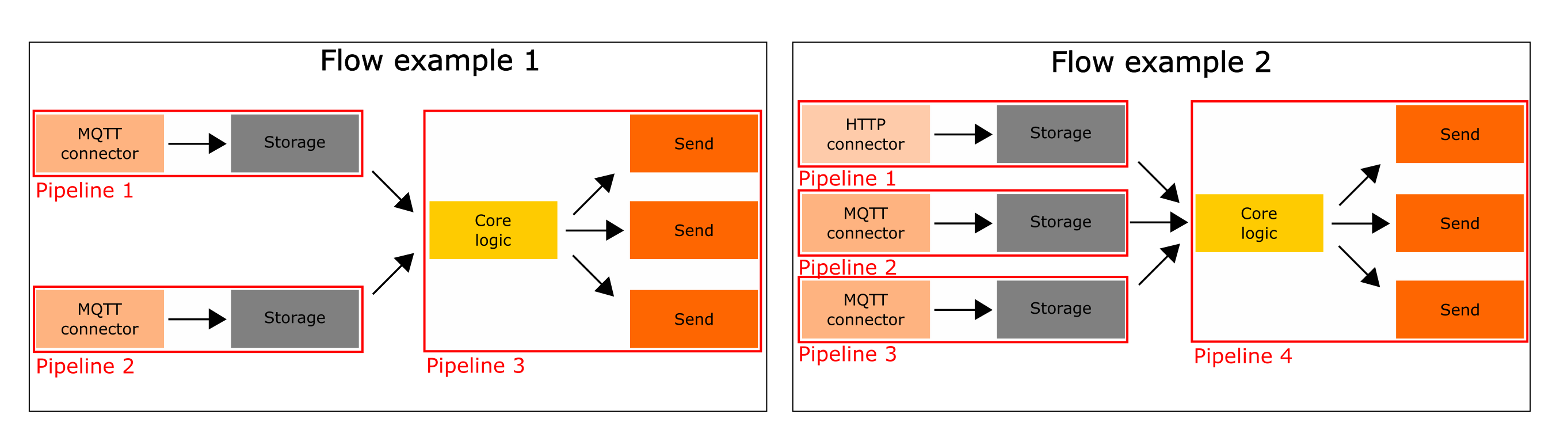
Core logic as heart of the flow
Wiredflow can be used simply to retrieve and save data. However, the tool's full potential is revealed when the need arises to perform custom data transformations.
To configure custom processing stage in the pipeline, the with_core_logic() method is used.
In this section of the documentation, however, we will cover only
a small part of the functionality. The customization process is
described in more detail in the "Customization" section.
For now, it will be enough to keep in mind that all local storage that is in the service is available in the core logic stage.
How to configure flow with several pipelines
It's quite simple. The syntax of the build will not differ from the previous examples.
An updated assignment to complicate the service that was partly configured in sections "Single thread service with HTTP connector" and "Single thread service with MQTT connector":
- It is required to run pipelines that get information about integers in one service. There are 2 pipelines required: 1) get random numbers via HTTP get request and 2) get ordered numbers via MQTT
- Every 15 seconds there is a need to download all numbers from local storages and output
them to the terminal using
print()
The code below will handle the task described:
from wiredflow.main.build import FlowBuilder
from wiredflow.mocks.demo_bindings_threads import remove_temporary_folder_for_demo, launch_demo_for_complex_case
def print_into_terminal(**kwargs):
# Through storages we can obtain data from other pipelines
db_connectors = kwargs['db_connectors']
# Load all currently available integers
http_integers = db_connectors['http_numbers'].load()
mqtt_integers = db_connectors['mqtt_numbers'].load()
http_integers = list(map(lambda x: int(x['Generated random number']), http_integers))
mqtt_integers = list(map(lambda x: int(x['Generated number']), mqtt_integers))
print(f'\nCustom logic checkout:')
print(f'HTTP integers: {http_integers}')
print(f'MQTT integers: {mqtt_integers}')
def launch_multiple_pipelines_flow():
"""
Example of how to configure and launch flow with several pipelines
"""
flow_builder = FlowBuilder()
# Pipeline for HTTP numbers processing
flow_builder.add_pipeline('http_numbers', timedelta_seconds=10)\
.with_http_connector(source='http://localhost:8027',
headers={'accept': 'application/json',
'apikey': 'custom_key_1234'})\
.with_storage('json')
# Pipeline for MQTT data processing
flow_builder.add_pipeline('mqtt_numbers') \
.with_mqtt_connector(source='localhost', port=1883,
topic='/demo/integers',
username='wiredflow', password='wiredflow') \
.with_storage('json')
# Add very simple custom logic as separate pipeline
flow_builder.add_pipeline('custom_logic', timedelta_seconds=15)\
.with_core_logic(print_into_terminal)
flow = flow_builder.build()
# Or simply flow.launch_flow()
# if there is no need to launch local demo http server
launch_demo_for_complex_case(flow, execution_seconds=30)
if __name__ == '__main__':
remove_temporary_folder_for_demo()
launch_multiple_pipelines_flow()
Now there is more code than there was in the first examples. However, it is in no way comparable to the complexity of the logic of the service itself. In fact, we're doing a great job. Let's take a closer look at what was done:
- The service collects data from two sources. One source supplies data via HTTP requests (batch data processing logic), the second via MQTT (continuous streaming workflow)
- All incoming data is saved in storages (for now, just files)
- Each pipeline has its own ETL task, which it performs with specified periodicity (differs for different pipelines)
- The custom logic (so far very simple) has been implemented and integrated into service
The service structure visualization:
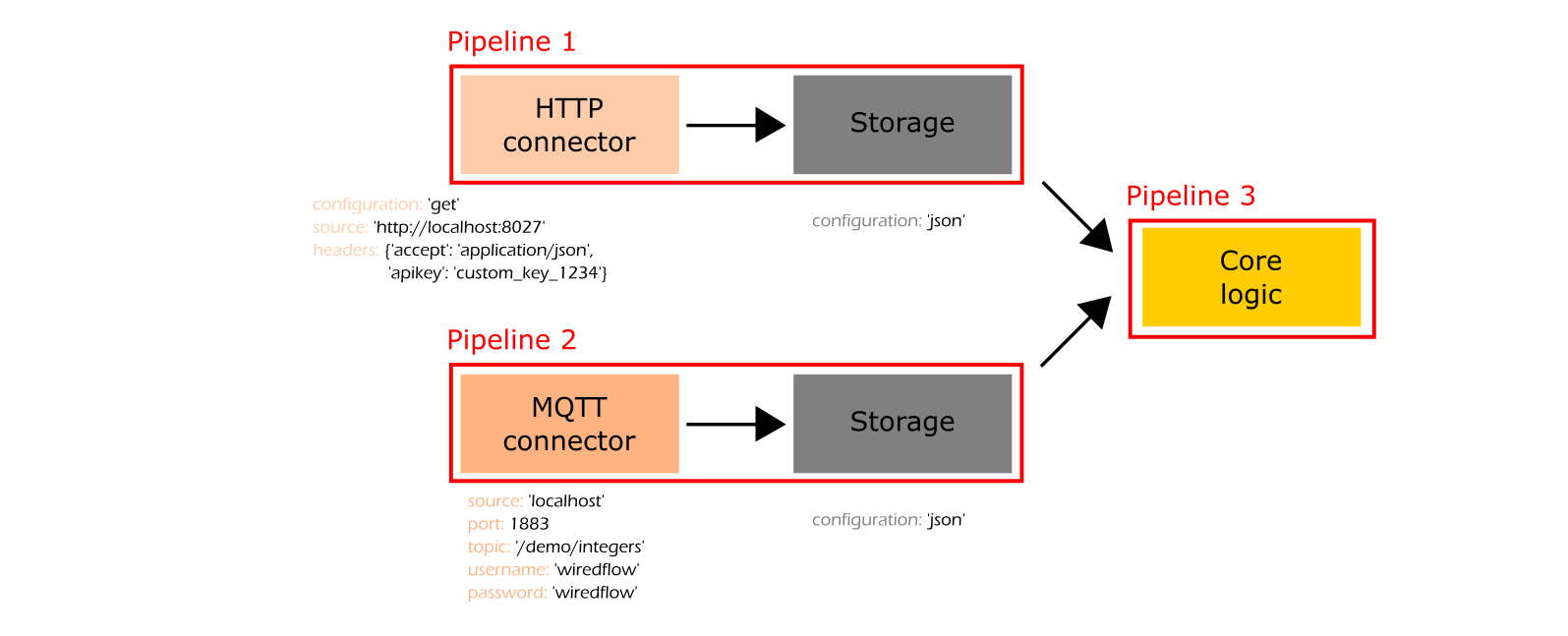
As can be seen from the code snippet above and from service visualization, a custom function has been implemented to integrate business logic of the proposed service via "core logic" stage.
Sharing error messages
We talked a lot above about the fact that if you run the service through a single entry point, it will effectively share errors. We suggest using an example to figure out how it works. Let's modify our custom function so that it crashes with an error. And run the code.
def print_into_terminal(**kwargs):
raise ValueError('Cannot print messages!')
Then the following messages will appear in the logs as soon as wiredflow starts the pipeline with custom logic:
2023-04-16 18:55:07.914 | INFO | wiredflow.main.flow:launch_pipeline:140 - Service failure due to "Cannot print messages!". Stop pipeline "custom_logic" execution
2023-04-16 18:55:10.131 | INFO | wiredflow.main.actions.action_input_http:execute_action:43 - Service failure due to "Cannot print messages!". Stop pipeline "http_numbers" execution
2023-04-16 18:55:10.131 | INFO | wiredflow.main.flow:launch_flow:79 - Flow finish execution
Disclaimer: In the example above, even after the service
has stopped, the logs in the terminal will still appear.
This is because the mock servers (data sources) are still running.
That's how it should be - the main thing is to see that
the service has stopped working (look for Flow finish execution)