Quick start
Welcome to the wiredflow documentation section exploring use cases!
Below, we take a look at what ETL (Extract, Transform, Load) services, detailing at each step what we're doing and why, write our own services to solve toy tasks, and configure advanced services.
The only skill required to begin studying is the ability to use Python. All other technologies will be covered when necessary. We'll go step by step, detailing at each step what we're doing and why.
What are ETL services and why are they needed?
ETL pipelines are needed when it is necessary to automatically retrieve data from somewhere (extract), do something with it (transform), and then save it to a new place (load), and sometimes repeat this task (schedule). Feel free to skip some steps - for examples just extract and load data is also ok. - You are still need ETL framework.
ETL tasks are similar to backend logic. Except that when the backend maintains a website, it usually runs tasks at the user's request (event based). Classic ETL pipelines usually use a fixed schedule. Obviously, when processing data from sensors, ETL services are also configured to run tasks according to events (but let's reserve that topic for future sections).
There are many things that can be done with ETL pipelines - gathering data to train machine learning models, running background processes to synchronize databases, send alerts and messages to users at particular time of the day and much more. Usually these are processes that no one sees. But, nevertheless, many services cannot manage without them.
Since such processes are critical, developers quite often have to write ETL-related services. Therefore, there are many tools that can automate the launch of such services, speed up their development and simplify monitoring. There is a short list with such a tools:
And, definitely, wiredflow
What is Application Programming Interface (API)
First, let's review the mechanisms that allow services to "communicate" with each other. For example, if any server runs a program that counts something, a special interface is developed for this program.
Then other programs and users using this interface can "communicate" with this program: it becomes possible to request data and send their own data. Frequently, ETL services collect data using APIs from external services, apply some transformations to it, and then store it. One of the most popular ways of communication between services is the HTTP/HTTPS protocol.
Therefore, most examples of using ETL services are based on processing HTTP requests. For example, you can use the GET method to obtain data from the service. So when we request data, we will use the GET method of the HTTP protocol in the examples below.
How to use wiredflow for ETL construction
Start with installation - it is pretty easy:
pip install wiredflow
If you use poetry:
poetry add wiredflow
Now you can open your IDE and create the file quick_start.py. We begin our journey in ETL service design!
We suggest starting with a simple example that does two things:
- Runs a local HTTP server that can handle GET HTTP requests. It always returns the same phrase: Hello world!
- Runs a configured ETL service which send GET request to local server every 60 seconds and save message into JSON file
The code to run the whole example is shown below:
from wiredflow.main.build import FlowBuilder
from wiredflow.mocks.demo_bindings_threads import remove_temporary_folder_for_demo,\
launch_demo_with_int_hello_world_connector
def wiredflow_hello_world():
"""
Quick example, which show how to configure and launch very simple ETL pipeline
"""
# Initialize builder to configure ETL services
flow_builder = FlowBuilder()
# Repeat actions in pipeline every 1 minute - send GET request and store response
flow_builder.add_pipeline('hello_world', timedelta_seconds=60)\
.with_http_connector(source='http://localhost:8025',
headers={'accept': 'application/json',
'apikey': 'custom_key_1234'})\
.with_storage('json', preprocessing='add_datetime')
# Configure service and launch it
flow = flow_builder.build()
# Or simply flow.launch_flow()
# if there is no need to launch local demo http server
launch_demo_with_int_hello_world_connector(flow, execution_seconds=20)
if __name__ == '__main__':
remove_temporary_folder_for_demo()
wiredflow_hello_world()
The structure of the obtained service can be represented as follows:
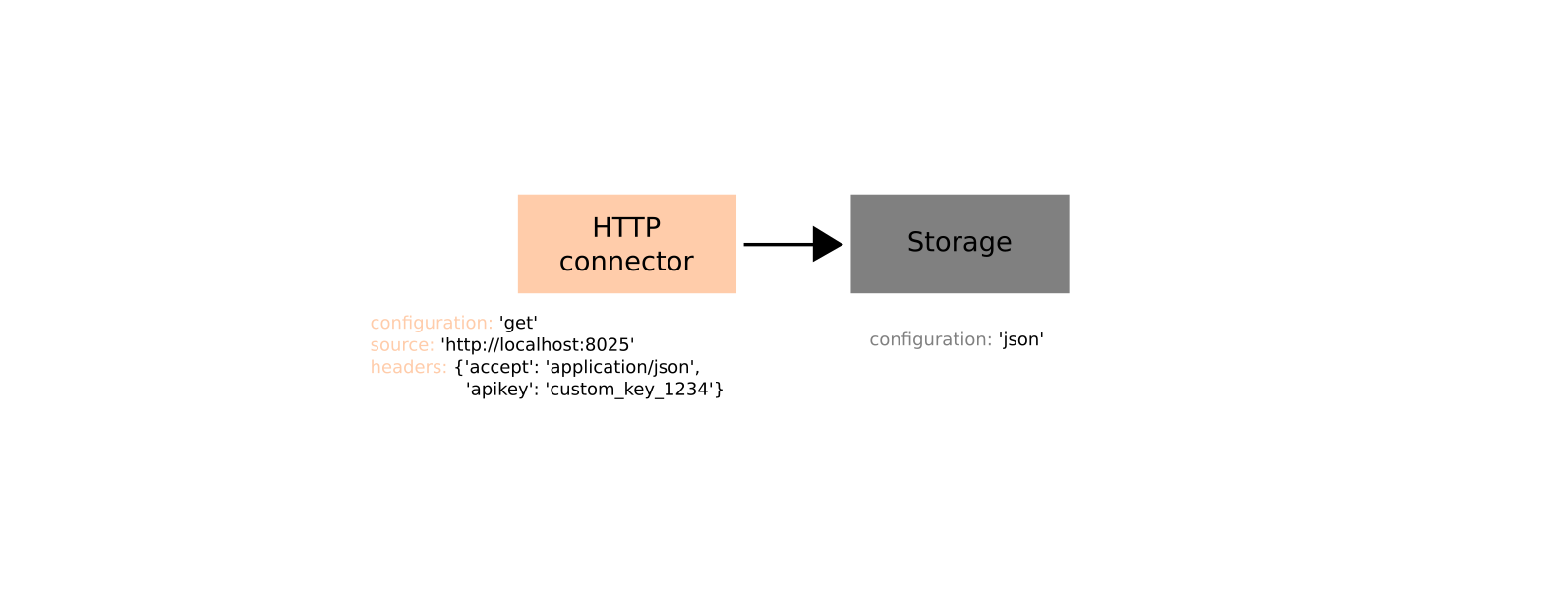
You can try running this code and see the result. Service sends GET HTTP request, gets message and saves it in JSON file - then repeat such an action every 60 seconds.
Output should look something like this:
2023-04-11 14:33:40.480 | INFO | wiredflow.main.flow:launch_flow:65 - Launch service with 1 pipelines using thread mode
2023-04-11 14:33:40.480 | INFO | wiredflow.mocks.http_server:_start_mock_http_server:150 - Start mock HTTP server in separate process: 127.0.0.1, port 8025. Execution timeout, seconds: 20
2023-04-11 14:33:40.481 | INFO | wiredflow.main.pipeline:run:155 - Launch pipeline "hello_world". Execution timeout, seconds: 20
2023-04-11 14:33:40.485 | DEBUG | wiredflow.main.store_engines.json_engine.json_db:save:37 - JSON info. Storage json_in_hello_world successfully save data in .../wiredflow/files/json_in_hello_world.json
2023-04-11 14:33:50.495 | INFO | wiredflow.wiredtimer.timer:will_limit_be_reached:44 - WiredTimer info: timeout was reached
2023-04-11 14:33:50.495 | INFO | wiredflow.main.flow:launch_flow:79 - Flow finish execution
2023-04-11 14:34:00.503 | INFO | wiredflow.mocks.http_server:_start_mock_http_server:165 - WiredTimer info: timeout was reached
Congratulations! You have launched ETL service. Next, we will analyze each line in detail, so that you will have no doubt that wiredflow is a simple tool.
Builder as core of the system
The explanation starts with the most important element in wiredflow: the Builder. Builder is a programming pattern which allows you to design various Python objects by flexible way.
FlowBuilder in wiredflow allows you to build ETL services (flows) with
different structure and for different tasks. This is a pretty flexible tool.
Services consist of pipelines. The Builder can compose services with a lot of pipelines.
However, in this simple example, we have configured the service with only one pipeline for clarity.
from wiredflow.main.build import FlowBuilder
# Initialize builder to configure ETL services
flow_builder = FlowBuilder()
# Repeat actions in pipeline every 1 minute - send GET request and store response
flow_builder.add_pipeline('hello_world', timedelta_seconds=60)\
.with_http_connector(source='http://localhost:8025',
headers={'accept': 'application/json',
'apikey': 'custom_key_1234'})\
.with_storage('json', preprocessing='add_datetime')
# Configure service
flow = flow_builder.build()
To add pipelines to the service, method add_pipeline is used.
The key arguments in this method are:
pipeline_name- the name for the pipelines. This can be any string. The parameter can be empty, in which case wiredflow will generate its unique identifier. However, it is recommended to specify names for pipelines - it makes logging and debugging more convenient and user-friendlytimedelta_seconds- period with which it is required to restart this pipeline. For example, timedelta_seconds=60 means that all actions described in the pipeline will be repeated every minute (wiredflow has its own internal scheduler - it controls the tasks launching)
We have considered how to add pipelines to the service. However, for pipelines, it is necessary to specify the operations that shall be performed. Such operations are called stages. To define stage use one of the following methods:
with_configuration- add configuration stage (require custom implementation)with_http_connector- add HTTP connectorwith_mqtt_connector- add MQTT connectorwith_core_logic- add core logic (require custom implementation)with_storage- add storage to save passed datasend- add tool for sending messages (e.g. via HTTP POST request) to external services
The addition of each stage has additional parameters. We will deal with this list of parameters later.
For now it is important to keep in mind that in wiredflow there are these from which it is possible to build services.
When the service structure is defined, it is needed to execute the build() method and construct the service.
After that you can run the configured service
Demo bindings
When the service is configured to be used on real tasks, it is enough to execute the method launch_flow().
However, in the documentation examples and in the examples folder
it can be seen that special functions are used for launching.
For instance, in the current example launch_demo_with_int_hello_world_connector was used.
These functions are only used in examples and tests to demonstrate ETL capabilities when interacting with third-party services. In other words, this function launches not only the service itself, but also in a separate process runs locally HTTP servers or other auxiliary services.
Nevertheless, the main parameter for both demo functions and launch_flow() will be execution_seconds:
execution_seconds- a time limit on how long the service will be computed in seconds. By default, this parameter is set to None. This means that the service will run all the time. If the limit is set, it will each pipeline running when the limit expires.
This parameter is very convenient to use when demonstrating services, preparing stands and testing.
To sum up, we have learned the syntax of the wiredflow library and how to run an ETL service. That's already pretty cool, but let's keep going!